QA over Documents
Use case
Suppose you have some text documents (PDF, blog, Notion pages, etc.) and want to ask questions related to the contents of those documents. LLMs, given their proficiency in understanding text, are a great tool for this.
In this walkthrough we'll go over how to build a question-answering over documents application using LLMs. Two very related use cases which we cover elsewhere are:
- QA over structured data (e.g., SQL)
- QA over code (e.g., Python)
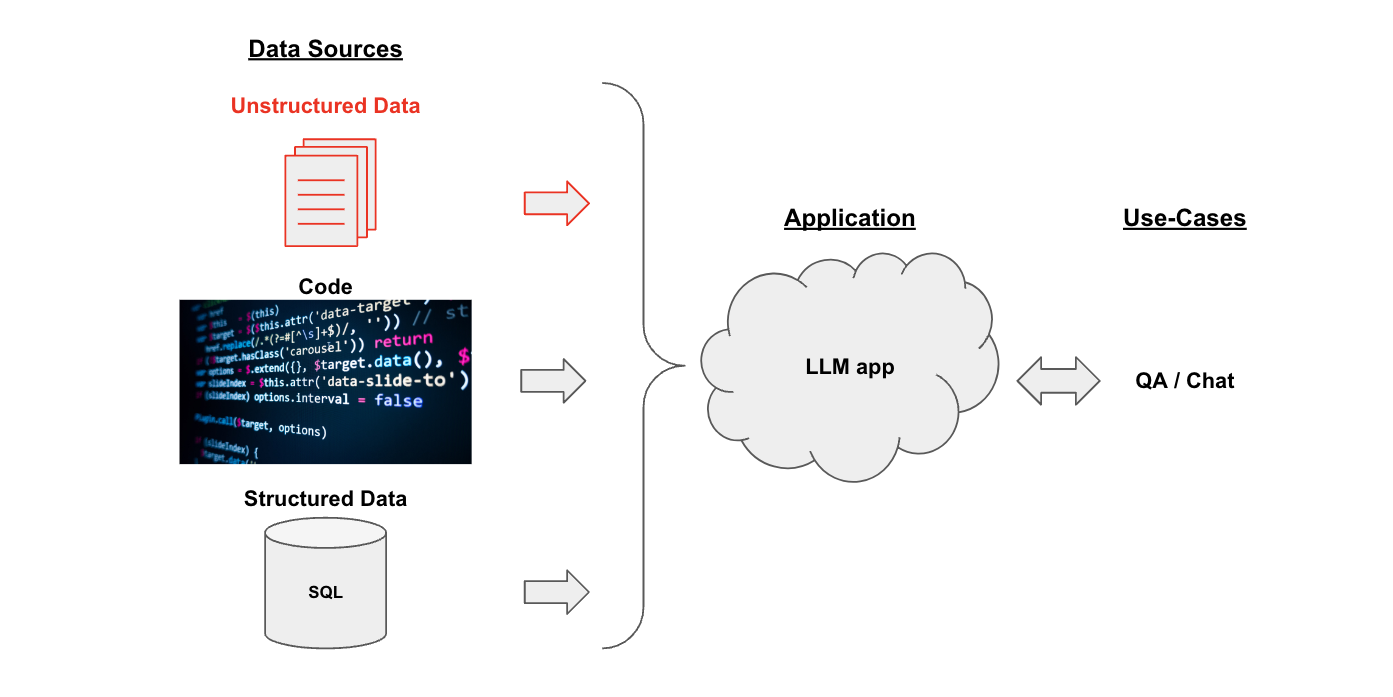
Overview
The pipeline for converting raw unstructured data into a QA chain looks like this:
Loading: First we need to load our data. Unstructured data can be loaded from many sources. Use the LangChain integration hub to browse the full set of loaders. Each loader returns data as a LangChainDocument.Splitting: Text splitters breakDocumentsinto splits of specified sizeStorage: Storage (e.g., often a vectorstore) will house and often embed the splitsRetrieval: The app retrieves splits from storage (e.g., often with similar embeddings to the input question)Generation: An LLM produces an answer using a prompt that includes the question and the retrieved dataConversation(Extension): Hold a multi-turn conversation by adding Memory to your QA chain.
Quickstart
To give you a sneak preview, the above pipeline can be all be wrapped in a single object: VectorstoreIndexCreator. Suppose we want a QA app over this blog post. We can create this in a few lines of code:
First set environment variables and install packages:
pip install openai chromadb
export OPENAI_API_KEY="..."
Then run:
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
API Reference:
- WebBaseLoader from
langchain.document_loaders - VectorstoreIndexCreator from
langchain.indexes
And now ask your questions:
index.query("What is Task Decomposition?")
' Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done using LLM with simple prompting, task-specific instructions, or human inputs. Tree of Thoughts (Yao et al. 2023) is an example of a task decomposition technique that explores multiple reasoning possibilities at each step and generates multiple thoughts per step, creating a tree structure.'
Ok, but what's going on under the hood, and how could we customize this for our specific use case? For that, let's take a look at how we can construct this pipeline piece by piece.
Step 1. Load
Specify a DocumentLoader to load in your unstructured data as Documents. A Document is a piece of text (the page_content) and associated metadata.
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
API Reference:
- WebBaseLoader from
langchain.document_loaders
Go deeper
Step 2. Split
Split the Document into chunks for embedding and vector storage.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
API Reference:
- RecursiveCharacterTextSplitter from
langchain.text_splitter
Go deeper
DocumentSplittersare just one type of the more genericDocumentTransformers, which can all be useful in this preprocessing step.- See further documentation on transformers here.
Context-aware splitterskeep the location ("context") of each split in the originalDocument:
Step 3. Store
To be able to look up our document splits, we first need to store them where we can later look them up. The most common way to do this is to embed the contents of each document then store the embedding and document in a vector store, with the embedding being used to index the document.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
API Reference:
- OpenAIEmbeddings from
langchain.embeddings - Chroma from
langchain.vectorstores
Go deeper
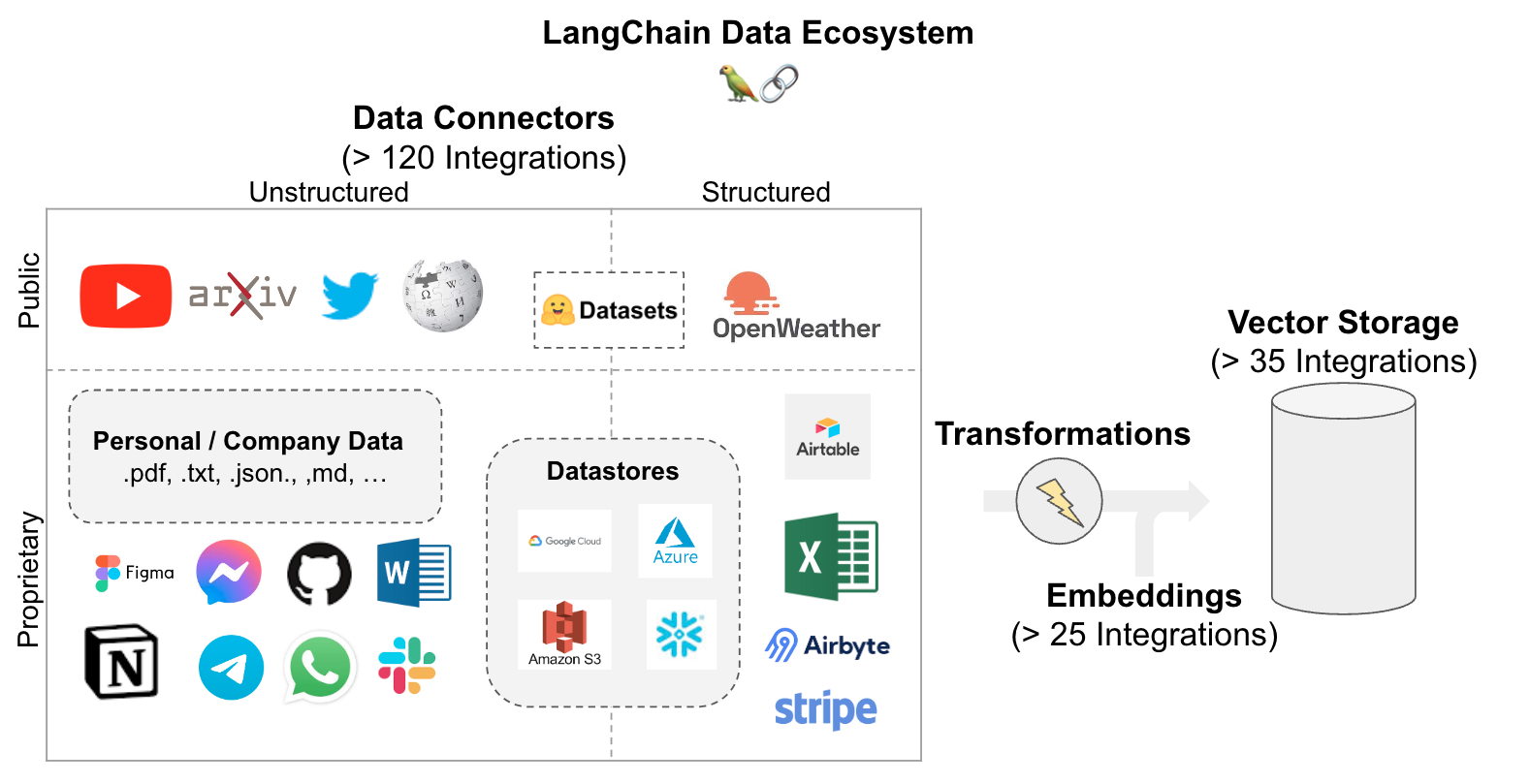
Browse the > 40 vectorstores integrations here.
See further documentation on vectorstores here.
Browse the > 30 text embedding integrations here.
See further documentation on embedding models here.
Here are Steps 1-3:
Step 4. Retrieve
Retrieve relevant splits for any question using similarity search.
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Go deeper
Vectorstores are commonly used for retrieval, but they are not the only option. For example, SVMs (see thread here) can also be used.
LangChain has many retrievers including, but not limited to, vectorstores. All retrievers implement a common method get_relevant_documents() (and its asynchronous variant aget_relevant_documents()).
from langchain.retrievers import SVMRetriever
svm_retriever = SVMRetriever.from_documents(all_splits,OpenAIEmbeddings())
docs_svm=svm_retriever.get_relevant_documents(question)
len(docs_svm)
API Reference:
- SVMRetriever from
langchain.retrievers
4
Some common ways to improve on vector similarity search include:
MultiQueryRetrievergenerates variants of the input question to improve retrieval.Max marginal relevanceselects for relevance and diversity among the retrieved documents.- Documents can be filtered during retrieval using
metadatafilters.
import logging
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),
llm=ChatOpenAI(temperature=0))
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
len(unique_docs)
API Reference:
- ChatOpenAI from
langchain.chat_models - MultiQueryRetriever from
langchain.retrievers.multi_query
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be approached?', '2. What are the different methods for Task Decomposition?', '3. What are the various approaches to decomposing tasks?']
5
Step 5. Generate
Distill the retrieved documents into an answer using an LLM/Chat model (e.g., gpt-3.5-turbo) with RetrievalQA chain.
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())
qa_chain({"query": question})
API Reference:
- RetrievalQA from
langchain.chains - ChatOpenAI from
langchain.chat_models
{
'query': 'What are the approaches to Task Decomposition?',
'result': 'The approaches to task decomposition include:\n\n1. Simple prompting: This approach involves using simple prompts or questions to guide the agent in breaking down a task into smaller subgoals. For example, the agent can be prompted with "Steps for XYZ" and asked to list the subgoals for achieving XYZ.\n\n2. Task-specific instructions: In this approach, task-specific instructions are provided to the agent to guide the decomposition process. For example, if the task is to write a novel, the agent can be instructed to "Write a story outline" as a subgoal.\n\n3. Human inputs: This approach involves incorporating human inputs in the task decomposition process. Humans can provide guidance, feedback, and suggestions to help the agent break down complex tasks into manageable subgoals.\n\nThese approaches aim to enable efficient handling of complex tasks by breaking them down into smaller, more manageable parts.'
}
Note, you can pass in an LLM or a ChatModel (like we did here) to the RetrievalQA chain.
Go deeper
Choosing LLMs
Browse the > 55 LLM and chat model integrations here.
See further documentation on LLMs and chat models here.
Use local LLMS: The popularity of PrivateGPT and GPT4All underscore the importance of running LLMs locally. Using
GPT4Allis as simple as downloading the binary and then:from langchain.llms import GPT4All
from langchain.chains import RetrievalQA
llm = GPT4All(model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin",max_tokens=2048)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
Customizing the prompt
The prompt in RetrievalQA chain can be easily customized.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
API Reference:
- RetrievalQA from
langchain.chains - PromptTemplate from
langchain.prompts
'The approaches to Task Decomposition are (1) using simple prompting by LLM, (2) using task-specific instructions, and (3) with human inputs. Thanks for asking!'
Return source documents
The full set of retrieved documents used for answer distillation can be returned using return_source_documents=True.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),
return_source_documents=True)
result = qa_chain({"query": question})
print(len(result['source_documents']))
result['source_documents'][0]
API Reference:
- RetrievalQA from
langchain.chains
4
Document(page_content='Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log", 'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:', 'language': 'en'})
Return citations
Answer citations can be returned using RetrievalQAWithSourcesChain.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm,retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
API Reference:
- RetrievalQAWithSourcesChain from
langchain.chains
{
'question': 'What are the approaches to Task Decomposition?',
'answer': 'The approaches to Task Decomposition include (1) using LLM with simple prompting, (2) using task-specific instructions, and (3) incorporating human inputs.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}
Customizing retrieved document processing
Retrieved documents can be fed to an LLM for answer distillation in a few different ways.
stuff, refine, map-reduce, and map-rerank chains for passing documents to an LLM prompt are well summarized here.
stuff is commonly used because it simply "stuffs" all retrieved documents into the prompt.
The load_qa_chain is an easy way to pass documents to an LLM using these various approaches (e.g., see chain_type).
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff")
chain({"input_documents": unique_docs, "question": question},return_only_outputs=True)
API Reference:
- load_qa_chain from
langchain.chains.question_answering
{'output_text': 'The approaches to task decomposition include (1) using simple prompting to break down tasks into subgoals, (2) providing task-specific instructions to guide the decomposition process, and (3) incorporating human inputs for task decomposition.'}
We can also pass the chain_type to RetrievalQA.
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),
chain_type="stuff")
result = qa_chain({"query": question})
In summary, the user can choose the desired level of abstraction for QA:
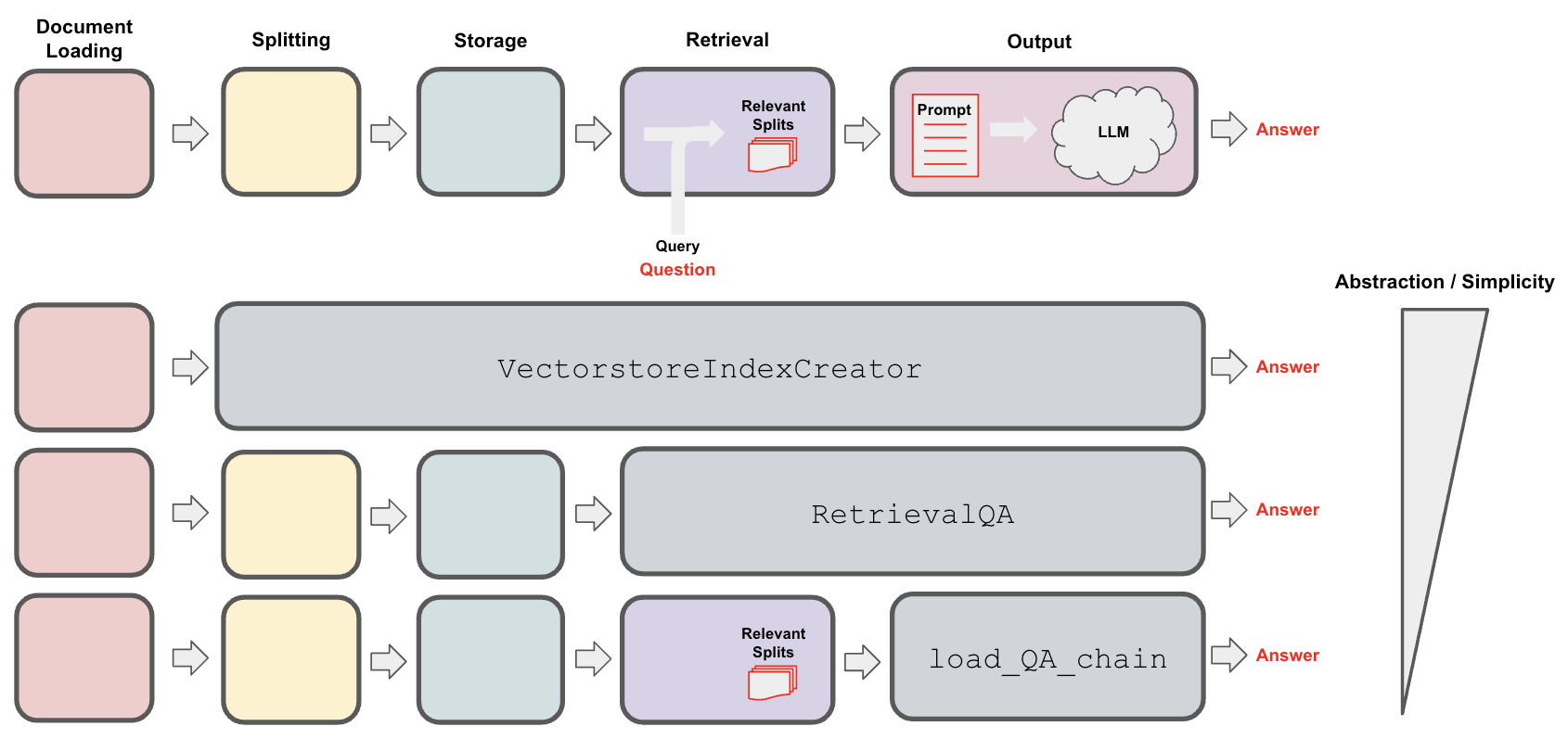
Step 6. Converse (Extension)
To hold a conversation, a chain needs to be able to refer to past interactions. Chain Memory allows us to do this. To keep chat history, we can specify a Memory buffer to track the conversation inputs / outputs.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
API Reference:
- ConversationBufferMemory from
langchain.memory
The ConversationalRetrievalChain uses chat in the Memory buffer.
from langchain.chains import ConversationalRetrievalChain
retriever = vectorstore.as_retriever()
chat = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
API Reference:
- ConversationalRetrievalChain from
langchain.chains
result = chat({"question": "What are some of the main ideas in self-reflection?"})
result['answer']
"Some of the main ideas in self-reflection include:\n1. Iterative improvement: Self-reflection allows autonomous agents to improve by refining past action decisions and correcting mistakes.\n2. Trial and error: Self-reflection is crucial in real-world tasks where trial and error are inevitable.\n3. Two-shot examples: Self-reflection is created by showing pairs of failed trajectories and ideal reflections for guiding future changes in the plan.\n4. Working memory: Reflections are added to the agent's working memory, up to three, to be used as context for querying.\n5. Performance evaluation: Self-reflection involves continuously reviewing and analyzing actions, self-criticizing behavior, and reflecting on past decisions and strategies to refine approaches.\n6. Efficiency: Self-reflection encourages being smart and efficient, aiming to complete tasks in the least number of steps."
The Memory buffer has context to resolve "it" ("self-reflection") in the below question.
result = chat({"question": "How does the Reflexion paper handle it?"})
result['answer']
"The Reflexion paper handles self-reflection by showing two-shot examples to the Learning Language Model (LLM). Each example consists of a failed trajectory and an ideal reflection that guides future changes in the agent's plan. These reflections are then added to the agent's working memory, up to a maximum of three, to be used as context for querying the LLM. This allows the agent to iteratively improve its reasoning skills by refining past action decisions and correcting previous mistakes."
Go deeper
The documentation on ConversationalRetrievalChain offers a few extensions, such as streaming and source documents.
Further reading
- Check out the How to section for all the variations of chains that can be used for QA over docs in different settings.
- Check out the Integrations-specific section for chains that use specific integrations.